Turning Claude into a DevOps assistant superhero
I've been experimenting with MCP servers in order to validate the feasibility of my dream to have LLMs relieve me of all the tedium in some aspects of DevOps work, and I have been blown away by the possibilities. In this post, I'll explain what MCPs are and go over a pretty cool demo of an MCP server I wrote for Kubernetes troubleshooting and monitoring.
MCP server crash course
Model Context Protocol (MCP) standardizes the way applications provide context to LLMs. To quote the official documentation:
Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.
What interested me in particular was the standardized integration with tools. Basically, when you register an MCP server, the LLM now knows about a set of commands which it can invoke to do something like retrieving information or performing an action. What I think is key here is that you control the code which gets executed, instead of allowing the LLM to go wild with code generation. It can pass parameters, but you are still responsible for what your code does.
I think it will make more sense if we look at a concrete example.
Kubernetes MCP server
As I am a DevOps engineer by day, my first reaction was to create a tool to help me in my day-to-day tasks. I quickly went through the quickstart tutorial on the MCP documentation page, which builds a simple weather tool. I was then ready to do something more interesting. I was quite skeptical, so I thought "let's create a READ ONLY Kubernetes monitoring and troubleshooting tool". Off I went generating a couple of functions with the help of Claude, to expose useful information from a Kubernetes cluster.
Here's the current list as of publishing this post:
-
get_namespaces(): List all available namespaces in the cluster -
list_pods(namespace=None): List all pods, optionally filtered by namespace failed_pods(): List all pods in Failed or Error statepending_pods(): List all pods in Pending state with reasons-
high_restart_pods(restart_threshold=5): Find pods with restart counts above threshold -
list_nodes(): List all nodes and their status -
node_capacity(): Show available capacity on all nodes -
list_deployments(namespace=None): List all deployments list_services(namespace=None): List all services-
list_events(namespace=None): List all events -
orphaned_resources(): List resources without owner references get_resource_yaml(namespace, resource_type, resource_name): Get YAML configuration for a specific resource
When you connect this MCP server to Claude using the claude_desktop_config.json, it automatically learns about those tools and what they can do. So, even before I demo anything, I am sure you are guessing that if you ask Claude to list all the pods in your cluster, it will call the list_pods tool and return a list of the pods. You are right, but that's not the cool part.
You can give Claude vague queries, or even better, complex queries, and it will put the pieces together in a smooth and beautiful way. Let's see it in action.
Magical demo
Before reading on, I encourage you to look at the actual conversation that took place and then look at the setup after.
Set up
Here is the scenario: I have deployed a cluster with 1 control plane node and 2 worker nodes. The following resources have been deployed in the cluster:
bad-image-pod.yaml- A pod with a non-existent imageresource-constrained-pod.yaml- A pod with very low resource limits that cause it to be throttled or OOM killed.bad-config-map.yamlandconfig-dep-pod.yaml- An application that depends on a ConfigMap with the wrong keys or values.resource-hog.yaml- Several large pods to force resource pressure on specific nodes (but not enough to crash them).flaky-script.yamlandflaky-deployment.yaml- A deployment with a liveness probe that occasionally fails, causing random restarts.
I have also deployed a couple of healthy resources. Everything is deployed either in the default, staging, or prod namespace.
So we have a mix of obvious issues and a few not so obvious, at least for an LLM I thought.
The test
I proceed to open Claude Desktop and ask What's the status of the Kubernetes cluster? Our dashboard metrics seem off. The assistant then uses the available tools (which currently are not that many) to gather information.

If you open the conversation, you can expand the calls to the tools to see the parameters that are passed and the response that is received.
Next, Claude provides the findings, identifying all the issues that are present and provides recommendations.

I pretend to fix the other issues and ask Claude to dive deeper into the tiny-api pod. It promptly identifies the issues and suggests how they can be resolved, explaining everything in detail. Bear in mind this takes a couple of seconds from me submitting the query to getting the response back.

Now here I can imagine someone saying "These are trivial issues, I can spot them from miles away!" Trivial or not, the fact that they get spotted in a couple of seconds and relieve me from chaining commands, slogging through walls of logs and jumping from one server to another is fascinating to me. And this is only "read-only" DevOps Claude. Soon I'll give it power to execute curated commands, and things will get even more interesting.
Finally, I deploy resource-hog.yaml and pretend that I am getting pinged for high resource usage.
Claude swiftly calls a few tools and sees right through my attempt to fool it by specifically pointing out that this appears to be a load testing deployment.
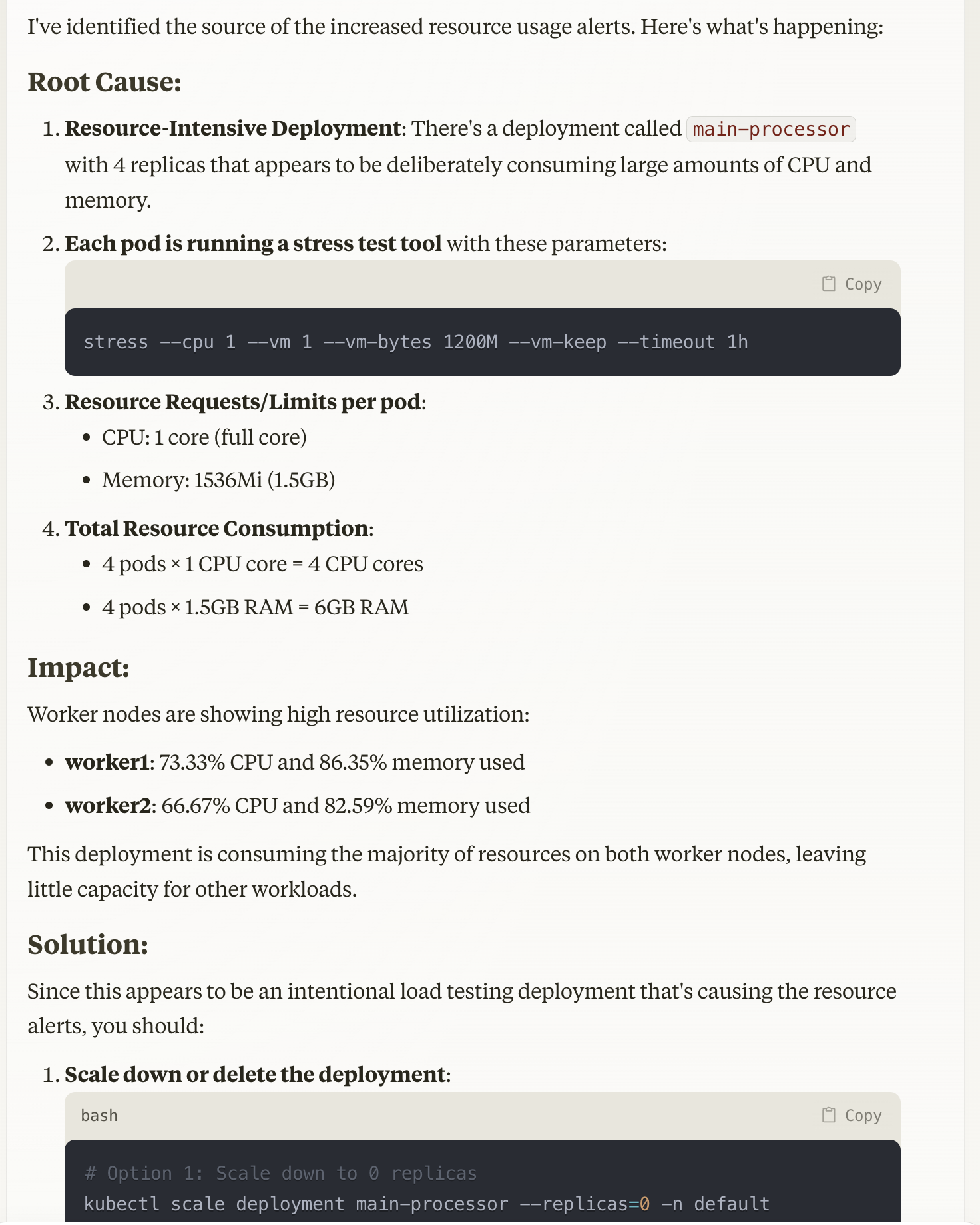
If you look carefully through the conversation, you will notice that although there are a limited set of functions, Claude is able to extract useful insights from the information returned by a tool that is not directly related to the tool's purpose. It is taking advantage of everything that it can get its hands on.
Why this matters
While the demo above might seem like a cool trick, the implications for DevOps teams are profound. Here's why I believe this approach represents a significant step forward:
-
Time savings - The most obvious benefit is pure efficiency. Tasks that traditionally required chaining multiple
kubectlcommands, parsing through logs, and cross-referencing documentation now happen in seconds. -
Reduced cognitive load - DevOps engineers often juggle multiple contexts and command syntaxes throughout the day. The ability to use natural language queries offloads the mental burden of remembering specific commands, flags, and output formats. This mental energy can be redirected to solving more complex problems.
-
Democratized troubleshooting - This approach lowers the barrier to entry for Kubernetes troubleshooting. Team members with less Kubernetes expertise can now perform initial diagnostics without waiting for a specialist, spreading knowledge more evenly across teams and reducing bottlenecks.
-
Context-aware responses - Unlike static dashboards or alerts that show isolated metrics, Claude can correlate information across different resources and namespaces to provide a more holistic view of what's happening. This contextual awareness helps identify root causes faster than looking at disconnected data points.
-
Customizable and extensible - Perhaps most importantly, the MCP approach means we control exactly what tools are exposed and how they execute. Unlike allowing an LLM to generate arbitrary code, we define the boundaries while still benefiting from the AI's natural language understanding and reasoning capabilities.
The combination of these benefits points toward a future where DevOps tooling becomes more intuitive and accessible while remaining secure and controlled. Rather than replacing DevOps engineers, tools like this augment their capabilities and free them to focus on high-value work that requires human judgment.
Final thoughts
With the current speed of advancements in AI and LLMs, it is easy to get desensitized to the things that become possible, but I personally find it exciting. I am super pumped by all the possibilities that open up with this kind of tool integration. It opens the door to really useful integrations and, more importantly, the ability to speed up and automate a lot of tedious work.
Keep in mind that in the MCP server used above, I have only implemented a handful of functions. I still haven't added querying for logs or the ability to execute commands.
I also have a list of ideas for other tools and integrations. Something I want to try out is setting up a cron job to ping Claude on some interval for status reports. I also want to integrate it with GitHub so it can create tickets, for example.
With the ability to understand natural language and unstructured information in such a way, the possibilities are endless. I am super excited to develop some tools for personal use but also potentially create products that others can benefit from, saving them time and effort. Let's see where this goes.